

وضعیت Reverting در SQL Server
 وضعیت Reverting در SQL Server چیست؟
وضعیت Reverting در SQL Server چیست؟
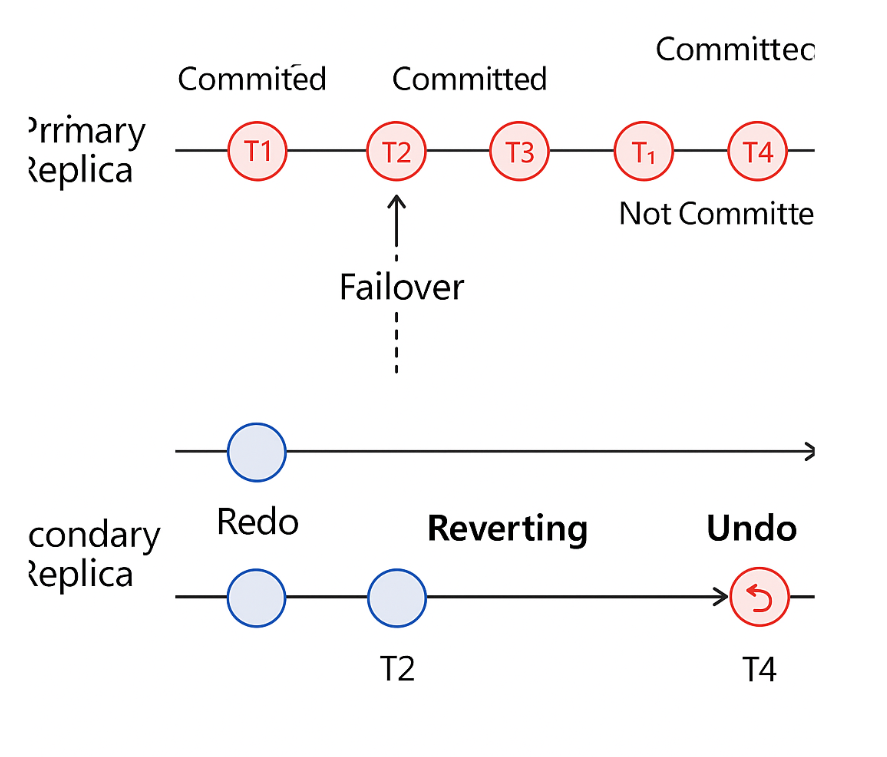
وضعیت «Reverting» زمانی رخ میدهد که یک تراکنش بزرگ در حین عملیات Failover (تغییر نقش اولیه و ثانویه) قطع شود. در این حالت، پایگاه داده ثانویه باید تغییراتی را که قبلاً اعمال کرده است، بازگرداند تا با پایگاه داده اولیه همگام شود. این فرآیند به عنوان “Undo of Redo” نیز شناخته میشود.Microsoft Learn
 علائم و پیامدهای وضعیت Reverting
علائم و پیامدهای وضعیت Reverting
- عدم همگامسازی پایگاه دادهها: در این وضعیت، پایگاه داده ثانویه همگامسازی را متوقف میکند و تغییرات جدید از پایگاه داده اولیه دریافت نمیکند. این میتواند منجر به از دست رفتن دادهها شود اگر پایگاه داده اولیه نیز از دست برود.
- گزارشهای داشبورد Always On: پس از Failover، داشبورد Always On ممکن است وضعیت “Not Synchronizing” را برای پایگاه داده اولیه و “Reverting” را برای پایگاه داده ثانویه نمایش دهد.Microsoft Learn+1eugenechiang.com+1
- خطاهای دسترسی به پایگاه داده ثانویه: در حین وضعیت Reverting، دسترسی به پایگاه داده ثانویه ممکن است با خطاهایی مانند پیام 922 یا خطای ورود 18456 مواجه شود.Microsoft Learn
 برآورد زمان باقیمانده در وضعیت Reverting
برآورد زمان باقیمانده در وضعیت Reverting
برای برآورد زمان باقیمانده در این وضعیت، میتوانید از روشهای زیر استفاده کنید:
- استفاده از جلسه Extended Events به نام AlwaysOn_health: این جلسه هر پنج دقیقه یک بار پیشرفت وضعیت Reverting را گزارش میدهد. برای مشاهده این گزارشها، به SSMS متصل شده و مسیر Management > Extended Events > Sessions را دنبال کنید و جلسه AlwaysOn_health را مشاهده کنید.Microsoft Learn+1MSSQLTips+1
- استفاده از Performance Monitor: میتوانید از شمارندههای عملکردی مانند SQL Server:Database Replica:Total Log Requiring Undo و SQL Server:Database Replica:Log Remaining for Undo برای نظارت بر پیشرفت فرآیند Reverting استفاده کنید.Database Administrators Stack Exchange+5Microsoft Learn+5GitHub+5
 اقدامات پیشنهادی در وضعیت Reverting
اقدامات پیشنهادی در وضعیت Reverting
- صبر کنید تا فرآیند Reverting کامل شود: این فرآیند ممکن است زمانبر باشد، به ویژه اگر تراکنشهای بزرگی در حال بازگردانی باشند.
- اضافه کردن یک Replica ثانویه جدید: اگر فقط دو Replica در گروه در دسترس دارید، اضافه کردن یک Replica ثانویه جدید میتواند به حفظ در دسترس بودن و همگامسازی کمک کند.Microsoft Learn
- بهروزرسانی مسیرهای مسیریابی خواندن: در صورت نیاز، مسیرهای مسیریابی خواندن را به Replica اولیه یا Replica ثانویه دیگر هدایت کنید تا بار کاری خواندن تحت تأثیر قرار نگیرد.
 اقدامات احتیاطی
اقدامات احتیاطی
- از Failover به Replica در وضعیت Reverting خودداری کنید: انجام این کار میتواند منجر به پایگاه دادهای غیرقابل استفاده شود که نیاز به بازیابی از پشتیبان دارد.
- از راهاندازی مجدد نمونه Replica ثانویه خودداری کنید: این کار فرآیند Reverting را تسریع نمیکند و ممکن است وضعیت پایگاه داده را بدتر کند.
 پیشگیری از وضعیت Reverting
پیشگیری از وضعیت Reverting
برای جلوگیری از ورود به وضعیت Reverting، قبل از انجام Failover، وجود تراکنشهای بزرگ را بررسی کنید. میتوانید از کوئری زیر برای شناسایی تراکنشهای باز استفاده کنید:eugenechiang.com+1Microsoft Learn+1
Code |
SELECT tat.transaction_begin_time, GETDATE() AS ‘current_time’, es.program_name, es.login_time, es.session_id, tst.open_transaction_count, eib.event_info FROM sys.dm_tran_active_transactions tat JOIN sys.dm_tran_session_transactions tst ON tat.transaction_id = tst.transaction_id JOIN sys.dm_exec_sessions es ON tst.session_id = es.session_id CROSS APPLY sys.dm_exec_input_buffer(es.session_id, NULL) eib WHERE es.is_user_process = 1 ORDER BY tat.transaction_begin_time ASC; |
این کوئری زمان شروع تراکنشهای فعال و اطلاعات مربوط به آنها را نمایش میدهد. اگر تراکنشهای بزرگی در حال اجرا هستند، قبل از انجام Failover منتظر بمانید تا این تراکنشها کامل شوند.
برای اطلاعات بیشتر و جزئیات دقیقتر، میتوانید به مقاله اصلی در Microsoft Learn مراجعه کنید:
 Troubleshoot an Availability Group database in reverting state
Troubleshoot an Availability Group database in reverting state
مقاله مایکروسافت بهطور کامل مشکلات مربوط به وضعیت Reverting در Availability Group را پوشش میدهد، اما در عمل، DBAها معمولاً با سناریوهایی مواجه میشوند که فراتر از توضیحات رسمی هستند. در ادامه چند مورد کاربردی، تجربی و تکمیلی آوردهام که میتوانند بهعنوان اطلاعات اضافهشده به داکیومنت اصلی تلقی شوند:
 1. تشخیص دقیق از طریق فایلهای لاگ SQL Server
1. تشخیص دقیق از طریق فایلهای لاگ SQL Server
علاوه بر Extended Events، میتوان بهصورت مستقیم از SQL Server Error Log اطلاعات دقیقتری دریافت کرد:
Code |
EXEC xp_readerrorlog 0, 1, N‘reverting’, NULL, NULL, NULL, N‘desc’; در لاگها معمولاً عباراتی مانند زیر ظاهر میشوند: Always On: The database ‘MyDatabase’ on the secondary replica is in reverting state… |
این اطلاعات میتواند بهصورت real-time درصد پیشرفت Undo را نشان دهد و در اسکریپتهای مانیتورینگ قابل استفاده است.
2. مانیتورینگ پیشرفته با DMVهای ترکیبی
یک روش ترکیبی برای مانیتورینگ Reverting:
Code |
SELECT db_name(database_id) AS DatabaseName, redo_queue_size, redo_rate, log_send_queue_size, log_send_rate, estimated_data_loss, synchronization_state_desc, synchronization_health_desc, last_commit_time FROM sys.dm_hadr_database_replica_states WHERE is_local = 1; |
همچنین استفاده از این کوئری در کنار بررسی حجم تراکنشهای معوق در sys.dm_tran_version_store_space_usage میتواند میزان بار برگشتدادهشده را تخمین بزند.
 3. تجربه واقعی: زمانی که Reverting تا چند ساعت طول میکشد
3. تجربه واقعی: زمانی که Reverting تا چند ساعت طول میکشد
در تراکنشهای بزرگ (مثلاً عملیاتهای MERGE یا BULK INSERT با میلیونها ردیف)، فرآیند Undo ممکن است چند ساعت یا حتی روزها طول بکشد. پیشنهادات تجربی:
- اگر فقط یک Secondary دارید: بهتر است قبل از هر گونه اقدام، یک Replica جدید اضافه کنید.
- اگر نیاز به دسترسی فوری به داده دارید و Reverting بسیار کند است، بررسی سناریوی Force Failover with Data Loss میتواند گزینه اضطراری باشد.
 4. نکته امنیتی: تعامل با Transparent Data Encryption (TDE)
4. نکته امنیتی: تعامل با Transparent Data Encryption (TDE)
اگر دیتابیس شما TDE فعال دارد، فرآیند Redo/Undo به دلیل رمزگشایی و رمزگذاری مجدد صفحات ممکن است کندتر شود. بنابراین در این شرایط توصیه میشود:
- اطمینان از در دسترس بودن Certificate در هر Replica
- استفاده از دیسکهای سریع برای TempDB و Log
 5. گزارشگیری برای داشبوردهای مانیتورینگ (مثلاً در Power BI)
5. گزارشگیری برای داشبوردهای مانیتورینگ (مثلاً در Power BI)
برای گزارشگیری دقیق از وضعیت Reverting و ایجاد داشبورد، میتوانید وضعیت پایگاه دادهها را هر ۵ دقیقه ذخیره و تحلیل کنید:
Code |
SELECT GETDATE() AS [CheckTime], AG.name AS AGName, AR.replica_server_name, DB_Name(DB.database_id) as database_Name, HADRStates.synchronization_state_desc, HADRStates.synchronization_health_desc, HADRStates.recovery_lsn, HADRStates.truncation_lsn INTO AG_Replica_Status_History FROM sys.availability_groups AS AG JOIN sys.availability_replicas AS AR ON AG.group_id = AR.group_id JOIN sys.dm_hadr_database_replica_states AS HADRStates ON AR.replica_id = HADRStates.replica_id JOIN sys.databases AS DB ON DB.database_id = HADRStates.database_id WHERE HADRStates.synchronization_state_desc = ‘NOT SYNCHRONIZING’ OR HADRStates.synchronization_health_desc = ‘NOT_HEALTHY’; |
 6. اشتباهات رایج DBAها هنگام مواجهه با Reverting
6. اشتباهات رایج DBAها هنگام مواجهه با Reverting
نتیجه | اشتباه |
خراب شدن AG و نیاز به Restore | Force Failover قبل از اتمام Reverting |
شروع مجدد Undo و زمان بیشتر | Restart کردن Replica ثانویه |
آلودگی دیتابیس یا نیاز به بازیابی | Kill کردن Session مربوط به Undo |
 7. قابلیت استفاده در محیطهای Container یا Kubernetes
7. قابلیت استفاده در محیطهای Container یا Kubernetes
اگر از SQL Server در محیطهایی مثل Kubernetes استفاده میکنید، در صورت رخ دادن وضعیت Reverting:
- از خاموش شدن خودکار پاد (pod eviction) جلوگیری کنید.
- از Volumeهای با سرعت بالا و پایدار استفاده کنید (مثلاً SSD-backed PVC).
چطور میتونم در محیط تست reverting رو شبیه سازی کنم
برای شبیهسازی وضعیت Reverting در محیط تست SQL Server Always On Availability Group، باید شرایطی را ایجاد کنید که منجر به بازگشت تراکنشهای Redo شده در Replica ثانویه شود. این اتفاق زمانی میافتد که یک تراکنش بزرگ در حین Redo قطع شود (مثلاً در هنگام Failover یا قطع ارتباط).
در ادامه، یک سناریوی عملی گامبهگام برای شبیهسازی وضعیت Reverting آوردهام:
 سناریوی تست Reverting در SQL Server Always On
سناریوی تست Reverting در SQL Server Always On
پیشنیازها:
- یک Availability Group با حداقل یک Replica ثانویه.
- حالت Synchronous Commit فعال باشد.
- گزینه Readable Secondary روی Replica ثانویه فعال نباشد (تا دخالت نکند).
- Transaction log size مناسب (مثلاً 1 گیگ یا بیشتر).
 مرحله 1: ایجاد دیتابیس آزمایشی و اضافه کردن به AG
مرحله 1: ایجاد دیتابیس آزمایشی و اضافه کردن به AG
Code |
CREATE DATABASE TestRevert; GO — تغییر حالت به FULL برای AG ALTER DATABASE TestRevert SET RECOVERY FULL; GO — تهیه بکاپ و لاگ BACKUP DATABASE TestRevert TO DISK = ‘C:\Backups\TestRevert.bak’; BACKUP LOG TestRevert TO DISK = ‘C:\Backups\TestRevert.trn’; |
حالا این دیتابیس را به Availability Group اضافه کنید (از SSMS یا با اسکریپت).
 مرحله 2: ایجاد یک تراکنش بزرگ روی Replica اصلی
مرحله 2: ایجاد یک تراکنش بزرگ روی Replica اصلی
Code |
USE TestRevert; GO — جدول تستی با رکورد زیاد CREATE TABLE BigTransTest ( ID INT IDENTITY, Name CHAR(8000) DEFAULT REPLICATE(‘A’,8000) ); GO BEGIN TRAN; — ایجاد بار زیاد در لاگ (مثلاً 100,000 ردیف حدوداً 800MB) INSERT INTO BigTransTest DEFAULT VALUES GO 100000 — توجه: هنوز COMMIT نکنید |
در این لحظه، تراکنش هنوز در حال اجراست و در لاگ نوشته شده ولی Commit نشده است. Redo آن نیز به Replica ثانویه ارسال شده ولی نهایی نشده.
 مرحله 3: قطع ارتباط بین Replicaها (یا Failover اجباری)
مرحله 3: قطع ارتباط بین Replicaها (یا Failover اجباری)
روش 1: قطع ارتباط شبکه بین Replica اصلی و ثانویه
- از فایروال یا PowerShell دستور زیر:
powershell
Code |
New-NetFirewallRule –DisplayName “Block AG” –Direction Outbound –RemoteAddress <SecondaryIP> –Action Block |
روش 2: Failover بدون Commit
در یک SSMS دیگر، بدون اینکه تراکنش را Commit کنید، دستور زیر را بزنید:
Code |
— انجام Force Failover با احتمال از دست رفتن داده ALTER AVAILABILITY GROUP [YourAGName] FORCE_FAILOVER_ALLOW_DATA_LOSS; |
 نتیجه: Replica ثانویه وارد وضعیت Reverting میشود
نتیجه: Replica ثانویه وارد وضعیت Reverting میشود
بعد از برقراری ارتباط یا پایان Failover، وضعیت Replica ثانویه به حالت Reverting میرود، چون تراکنشی که Redo شده، در نهایت Commit نشده و باید Undo شود.
 مانیتور وضعیت Reverting
مانیتور وضعیت Reverting
از DMVها یا Extended Events برای مانیتور استفاده کنید:
Code |
SELECT DB_NAME(database_id) AS [Database], synchronization_state_desc, synchronization_health_desc, redo_queue_size, log_send_queue_size, log_send_rate, redo_rate FROM sys.dm_hadr_database_replica_states WHERE is_local = 1; |
یا در SSMS > Always On Dashboard > وضعیت دیتابیس را ببینید.
 پاکسازی تست
پاکسازی تست
برای حذف شرایط آزمایشی:
Code |
— در Replica اولیه DROP DATABASE TestRevert; اگر نمیتوانید پاک کنید چون در AG است، اول از AG خارج کنید: ALTER AVAILABILITY GROUP [YourAGName] REMOVE DATABASE TestRevert; DROP DATABASE TestRevert; |
استفاده از SQL Server Error Log و Extended Events برای مانیتورینگ وضعیتهایی مانند Reverting در Availability Group یک راه کمهزینه و دقیق برای مشاهده وضعیتهای بحرانی است. در ادامه، راهاندازی و تنظیم هر دو روش را با جزئیات و مثالهای عملی آوردهام:
 بخش اول: استفاده از SQL Server Error Log برای مانیتورینگ Reverting
بخش اول: استفاده از SQL Server Error Log برای مانیتورینگ Reverting
SQL Server بهطور خودکار پیامهای مربوط به Always On و Reverting را در Error Log مینویسد. برای مانیتور این پیامها:
1. اسکریپت جستجو در Error Log
Code |
— جستجوی وضعیت reverting EXEC xp_readerrorlog 0, 1, N‘reverting’, NULL, NULL, NULL, N‘desc’; |
2. جستجوی کلمات کلیدی مفید دیگر:
Code |
— پیامهای Always On EXEC xp_readerrorlog 0, 1, N‘Always On’, NULL, NULL, NULL, N‘desc’; — پیامهای مربوط به Undo و Redo EXEC xp_readerrorlog 0, 1, N‘redo’, NULL, NULL, NULL, N‘desc’; EXEC xp_readerrorlog 0, 1, N‘undo’, NULL, NULL, NULL, N‘desc’; |
 پیشنهاد برای مانیتورینگ مستمر
پیشنهاد برای مانیتورینگ مستمر
- این دستورات را میتوان بهصورت Job در SQL Agent اجرا کرد و نتایج را در یک جدول ذخیره کرد.
- همچنین میتوان یک هشدار ایمیلی تنظیم کرد (در ادامه مثال میزنم).
 بخش دوم: راهاندازی Extended Events برای مانیتور Reverting
بخش دوم: راهاندازی Extended Events برای مانیتور Reverting
گامبهگام برای ساخت Extended Event Session:
1. ایجاد Extended Event برای وضعیتهای HADR و Reverting
Code |
CREATE EVENT SESSION [AG_Reverting_Monitor] ON SERVER ADD EVENT sqlserver.error_reported ( WHERE (message LIKE ‘%reverting%’ OR message LIKE ‘%redo%’ OR message LIKE ‘%undo%’ OR message LIKE ‘%is not synchronizing%’ OR message LIKE ‘%unrecoverable%’ ) AND severity >= 10 ) ADD TARGET package0.event_file (SET filename = N‘C:\AG_Reverting_Monitor.xel’) WITH (STARTUP_STATE = ON); GO — شروع مانیتورینگ ALTER EVENT SESSION [AG_Reverting_Monitor] ON SERVER STATE = START; |
بررسی خروجی Extended Event:
برای دیدن پیامها:
Code |
— مشاهده پیامها از فایل SELECT event_data.value(‘(event/@name)[1]’, ‘varchar(50)’) AS EventName, event_data.value(‘(event/data[@name=”message”]/value)[1]’, ‘varchar(max)’) AS MessageText, event_data.value(‘(event/@timestamp)[1]’, ‘datetime2’) AS [TimeStamp] FROM ( SELECT CAST(event_data AS XML) AS event_data FROM sys.fn_xe_file_target_read_file(‘C:\AG_Reverting_Monitor*.xel’, NULL, NULL, NULL) ) AS X; |
 اضافه کردن هشدار ایمیلی (در صورت تمایل)
اضافه کردن هشدار ایمیلی (در صورت تمایل)
اگر Database Mail و Operator تنظیم شده باشد:
مثال ساده هشدار هنگام مشاهده Reverting در Error Log
Code |
EXEC msdb.dbo.sp_add_alert @name = N‘AG Reverting Detected’, @message_id = 0, @severity = 0, @enabled = 1, @delay_between_responses = 300, @include_event_description_in = 1, @notification_message = N‘Check Always On – possible Reverting status detected!’, @performance_condition = NULL, @event_description_keyword = N‘reverting’, @category_name = N‘[Uncategorized]’, @job_id = NULL; EXEC msdb.dbo.sp_add_notification @alert_name = N‘AG Reverting Detected’, @operator_name = N‘DBA Team’, @notification_method = 1; |
 نکته نهایی: محل ذخیره فایل XEL
نکته نهایی: محل ذخیره فایل XEL
مکان فایل XEL را در مسیر سریع و دارای فضای کافی قرار دهید. برای مثال:
Code |
‘C:\XEventsLogs\AG_Reverting_Monitor.xel’ یا مسیر شبکهای: |
آیا در حالتی که Reverting اتفاق میافتد دیتایی از دست میرود؟
پرسش بسیار مهمی است. پاسخ کوتاه این است:
 در حالت Reverting، دادهای از دست نمیرود، بلکه فقط دادههایی که هنوز Commit نشدهاند، Rollback میشوند.
در حالت Reverting، دادهای از دست نمیرود، بلکه فقط دادههایی که هنوز Commit نشدهاند، Rollback میشوند.
بیایید دقیقتر بررسی کنیم:
 Reverting چیست؟
Reverting چیست؟
در Availability Group، وقتی یک دیتابیس روی Secondary Replica در حال Redo کردن تراکنشهاست (یعنی عملیات مربوط به تغییرات روی Primary را بازپخش میکند)، اگر ارتباط قطع شود یا Failover نیمهکاره اتفاق بیفتد، ممکن است تراکنشهایی که Redo شدهاند ولی هنوز Commit نشدهاند، نیمهتمام بمانند.
در این حالت SQL Server دیتابیس را به حالت **Reverting** میبرد، یعنی میگوید:
“من تراکنشهایی را Redo کردهام که Commit نشدند، بنابراین باید آنها را Undo کنم (برگردانم) تا دیتابیس به حالت Consistent برگردد.”
 چه دادههایی ممکن است Rollback شوند؟
چه دادههایی ممکن است Rollback شوند؟
- فقط تراکنشهایی که در Primary هنوز Commit نشده بودند و در Secondary Redo شده بودند.
- این تراکنشها هرگز برای کاربران نهایی قابل مشاهده نبودهاند، چون Secondary به صورت Read-Only است (مگر اینکه Readable Secondary فعال باشد).
بنابراین، هیچ دادهای از دید کاربران از دست نمیرود.
 چه زمانی ممکن است داده از دست برود؟
چه زمانی ممکن است داده از دست برود؟
تنها زمانی که داده واقعاً از دست برود، زمانی است که:
- Failover اجباری با ALLOW_DATA_LOSS انجام شود، در حالی که:
- Secondary جلوتر از Primary باشد (نادر ولی ممکن در برخی وضعیتهای async یا sync شکستهشده).
- یا لاگها بین دو Replica تطابق نداشته باشند.
اما این به حالت Reverting ارتباطی ندارد.
جمعبندی
حالت | آیا دادهای از دست میرود؟ | توضیح |
Reverting |
| فقط تراکنشهای ناتمام Undo میشوند. |
Normal Redo |
| تراکنشها از روی لاگ بازپخش میشوند. |
Force Failover with Data Loss |
| ممکن است برخی تراکنشها از بین بروند. |
Crash بدون Availability Group | بسته به Recovery Mode | در FULL معمولاً نه. در SIMPLE ممکن است. |


منابع پیشنهادی برای مشاهده دیاگرامهای مرتبط با Always On
- مقاله SQLShack درباره Resynchronization در Availability Group
این مقاله شامل دیاگرامهایی است که فرآیند بازپخش لاگها (Redo) و بازگردانی تراکنشهای ناقص (Undo) را در سناریوهای مختلف، از جمله Failover، توضیح میدهد.
لینک: SQL Shack - مستندات رسمی مایکروسافت درباره Failover Modes
در این مستند، دیاگرامهایی برای درک بهتر حالتهای مختلف Failover در Always On Availability Groups ارائه شده است.
لینک: Microsoft Learn - مقاله SQLShack درباره سطوح Isolation در Always On
این مقاله به بررسی رفتار سطوح Isolation در Always On میپردازد و شامل دیاگرامهایی است که میتوانند به درک بهتر فرآیندهای Redo و Undo کمک کنند.
لینک: SQL Shack
با مراجعه به این منابع، میتوانید دیاگرامهای با کیفیت و توضیحات دقیقتری درباره فرآیندهای Redo، Undo و وضعیت Reverting در SQL Server Always On Availability Groups مشاهده کنید.اگر نیاز به راهنمایی بیشتر یا توضیحات اضافی دارید، خوشحال میشوم کمک کنم.SQL Shack+1SQL Shack+1
